In this work, we operationalize Native 100MP Text-to-Image Generation as a dedicated training and evaluation regime, significantly distinct from approaches of training-free resolution upscaling. To bridge existing multi-faceted gaps, we propose a comprehensive methodology framework spanning dataset, model, and benchmark:
(1) We introduce PixVerve-95K, the first large-scale, high-quality T2I dataset to push image resolution to 100MP. With a five-stage, automated data pipeline, we curate 95,735 100MP images with fine-grained annotations (5 types of metadata and 2 comprehensive captions), directly supporting the training or fine-tuning of T2I models at high resolutions.
(2) Based on our proposed PixVerve-95K, we first explore the attempt of generating 100MP images natively. Specifically, we extend existing T2I foundation models (including both latent diffusion models and pixel diffusion models) with three distinct training schemes, providing valuable insights and paving the way for future breakthroughs.
(3) To address the limitations of conventional T2I benchmarks, we construct PixVerve-Bench, a systematic, hierarchical evaluation protocol incorporating both traditional metrics and assessments based on Multimodal Large Language Models (MLLMs).
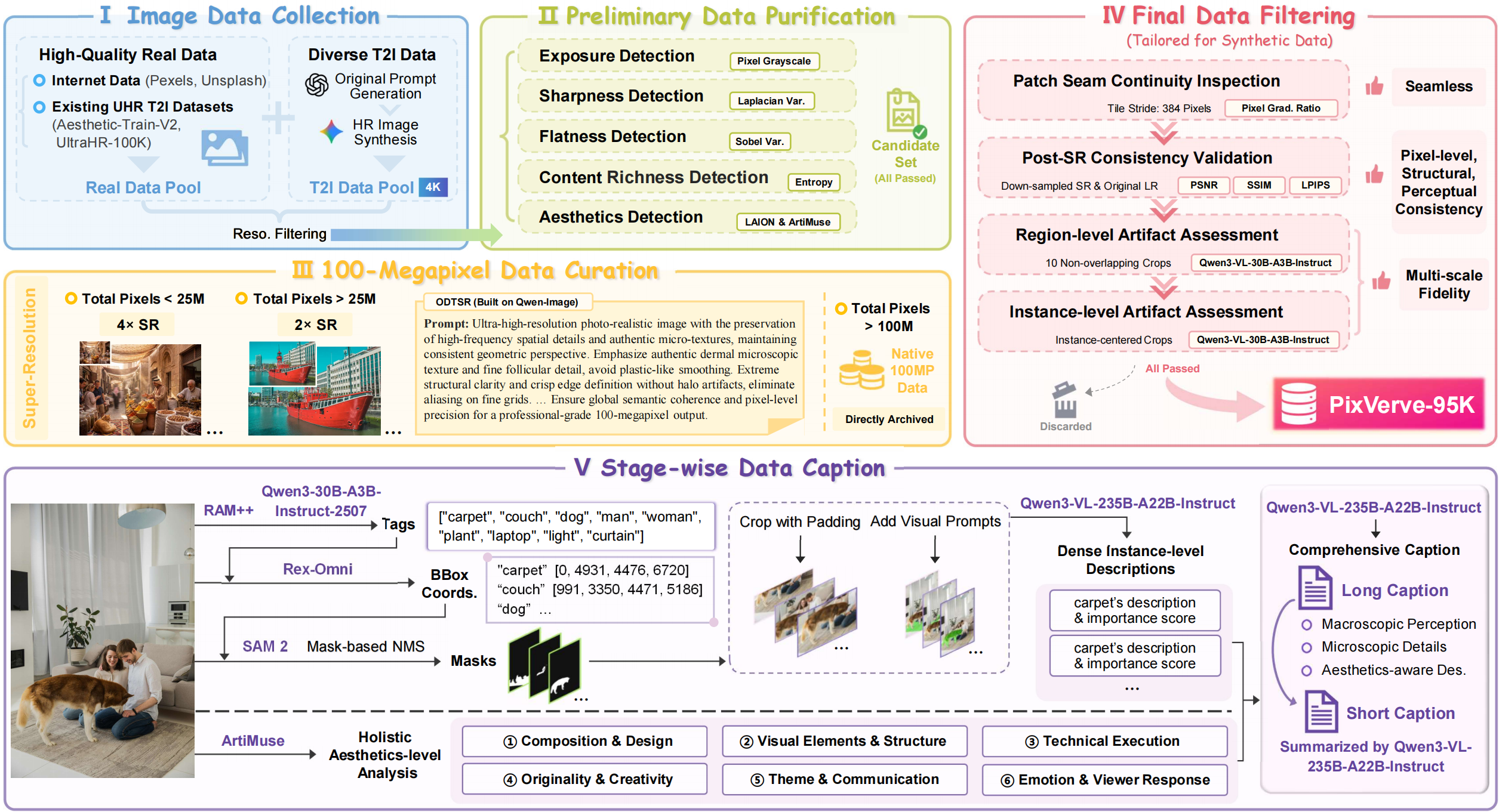
Our PixVerve-95K curation pipeline that includes: 1) High-quality and diverse raw image data acquisition. 2) Preliminary data purification comprising five parallel detection procedures. 3) 100MP data curation via super-resolution. 4) Final data filtering to ensure the quality of our synthetic data. 5) Stage-wise data caption pipeline carefully designed for UHR images.

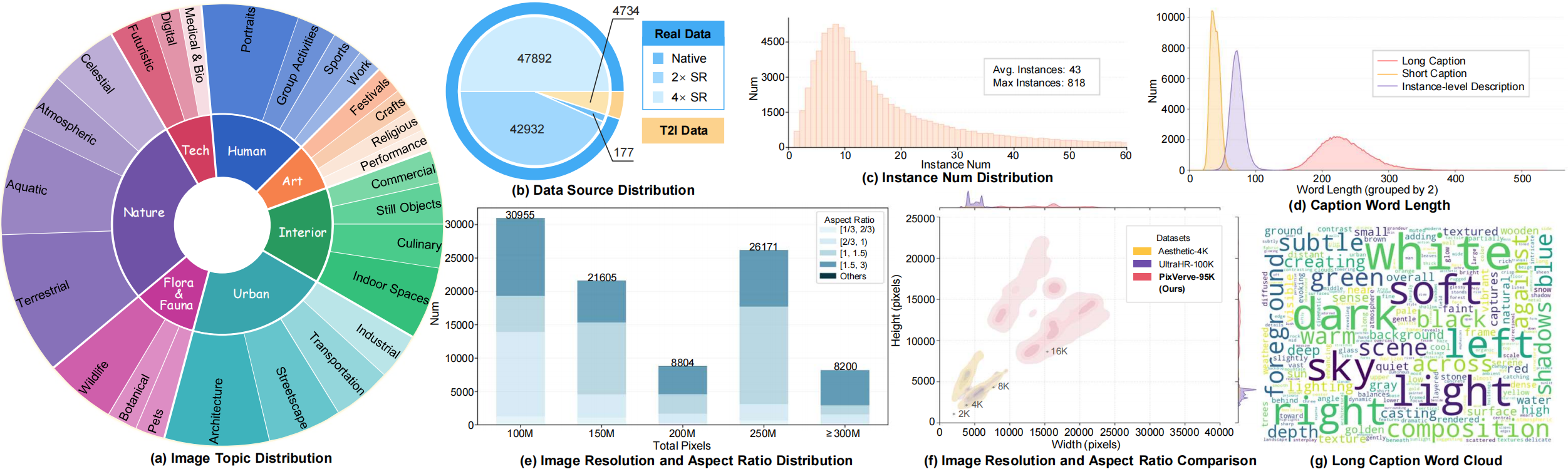

Attribute comparison with open-source UHR T2I datasets. Our PixVerve-95K dataset provides multi-dimensional, fine-grained metadata and significantly longer comprehensive captions. These structured annotations offer versatile utility for the community.
Training T2I foundation models at native 100MP poses great challenges due to the immense semantic complexity and vast pixel space. Bridging this gap necessitates a collaborative exploration of diverse architectural and optimization strategies. Based on PixVerve-95K, we conduct a multi-faceted exploration to retrofit T2I foundation models for native 100MP synthesis. Specifically, we investigate three distinct schemes to identify the optimal path. Please refer to our paper for more details.
(1) Full-Attention LDM Fine-tuning. As direct baselines, we perform full-parameter training and use LoRA for parameter-efficient fine-tuning (PEFT) on FLUX.2-klein-base-4B, respectively.
(2) Window-Attention Retrofitting and LDM Fine-tuning. To achieve a balance between performance and computational efficiency, we explore to refine the training strategy by introducing a local-to-global attention mechanism. We retrofit the joint attention in FLUX.2 into a dual-branch window-attention for both training and inference, without altering the core architecture of full-attention pretrained models.
(3) Patch-based Diffusion in Pixel Space. Motivated by recent promising pixel diffusion models, we explore a paradigm bypassing the latent space entirely. Following L2P, we adopt a patch-based pixel diffusion framework that decouples global structure from local refinement: a transformer backbone operates on large image patches for long-range semantics and spatial layout, while a lightweight head leverages contextual features and original noisy patches to reconstruct fine details. To enable training on a single GPU card, we further adaptively adjust the patch size to control the token count at higher resolutions.
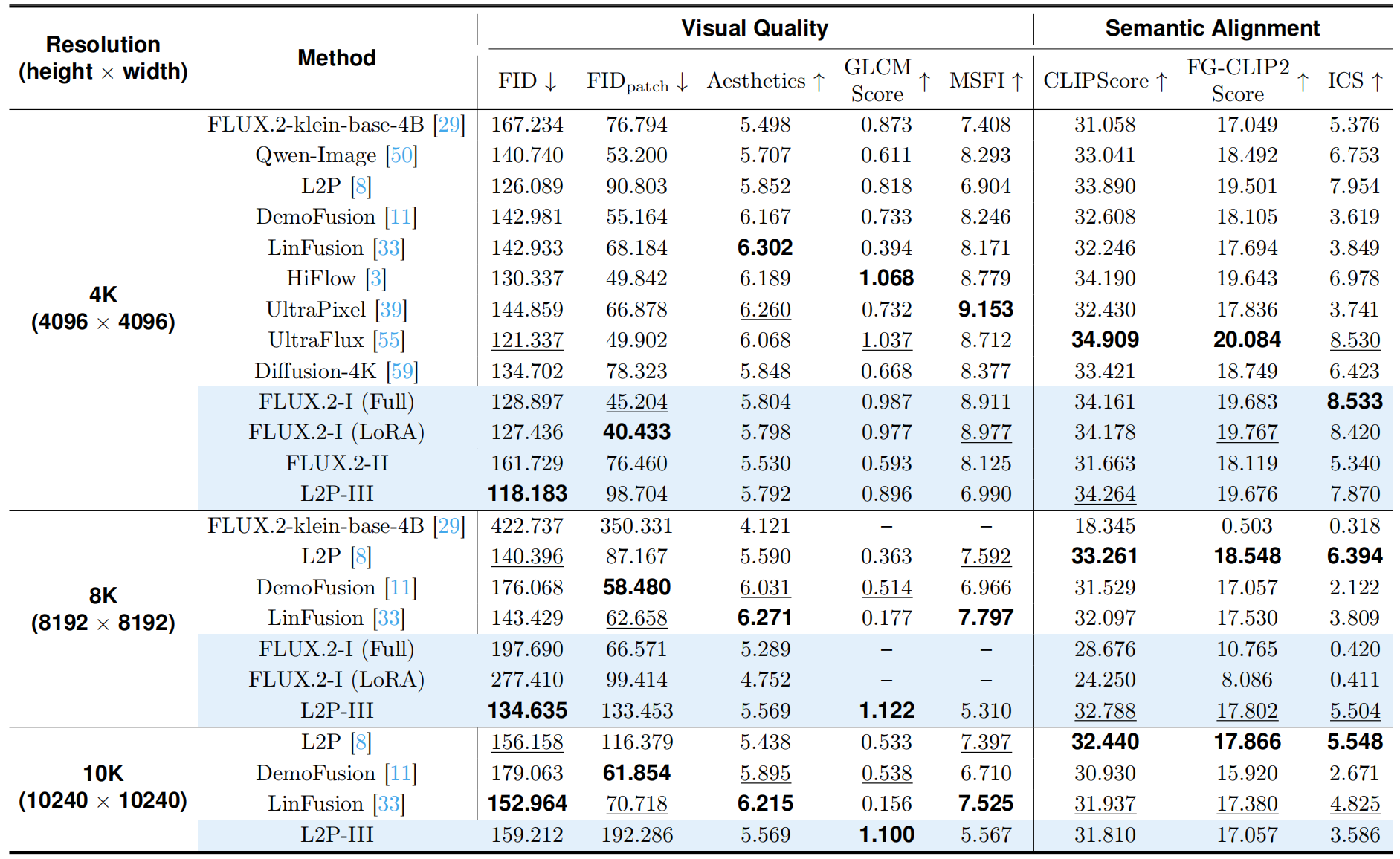
Quantitative comparison on PixVerve-Bench. MSFI (Multi-scale Fidelity Index) and ICS (Instance-centric Compliance Score) are our proposed Qwen3.5-based metrics for evaluating the visual quality and semantic alignment of UHR images, respectively. Please refer to our paper for more details. The best result is highlighted in bold, while the second-best result is underlined. -- indicates complete failures such as producing meaningless textures or black images, which are not applicable to the semantics-agnostic GLCM Score and MSFI.

(1) Full-attention LDM fine-tuning shows strong 4K adaptation but poor scalability. Direct fine-tuning effectively adapts local image statistics while preserving the semantic prior at 4K resolution, but it poses substantial challenges to scale up to 100MP due to the quadratic complexity of attention and requires more training strategies to handle the vast pixel space.
(2) Window-attention retrofitting achieves faster attention computation but with optimization challenges. This training scheme reduces computational costs for both training and inference, but it introduces optimization challenges that lead to noticeable performance degradation. In practice, the model requires more optimization steps to recover global communication, and the final quality is sensitive to the window size and aspect-ratio schedules.
(3) Patch-based pixel diffusion presents promising scalability but requires a patch-size trade-off. It is surprisingly observed that this pixel diffusion-based approach shows the most promising scalability among our explored schemes. It remains functional at 8K and 10K, and achieves much faster inference speed on a single GPU card. But the main limitation is the patch-size trade-off. To fit training into a single 96 GB GPU card, we adjust the patch size from 64 to 128 and 320 at the cost of coarser representations, reducing memory cost but weakening fine-detail reconstruction.
@misc{chen2026pixverveadvancingnativeuhr,
title={PixVerve: Advancing Native UHR Image Generation to 100MP with a Large-Scale High-Quality Dataset},
author={Haojun Chen and Haoyang He and Chengming Xu and Qingdong He and Junwei Zhu and Yabiao Wang and Zhucun Xue and Xianfang Zeng and Zhennan Chen and Xiaobin Hu and Hao Zhao and Yong Liu and Jiangning Zhang and Dacheng Tao},
year={2026},
eprint={2605.20147},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2605.20147},
}



